NirenbergCodonTable
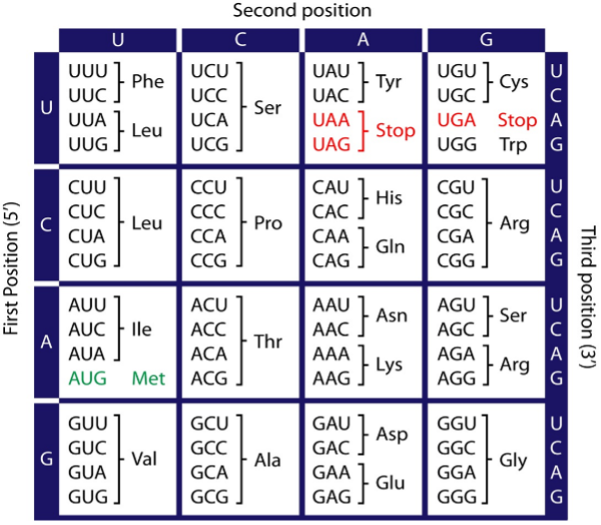
1 2025-01-22T09:20:32-05:00 George Shaohua Qiao 78e5371050dd5c0e21d36bad469c70d8d4be5464 225 1 This table demonstrates the specific promotion of three amino acids (Phe, Lys, and Pro) by triplets of one nucleotide (UUU, AAA, and CCC, respectively). plain 2025-01-22T09:20:32-05:00 George Shaohua Qiao 78e5371050dd5c0e21d36bad469c70d8d4be5464This page is referenced by:
-
1
2025-01-22T09:20:25-05:00
Chapter 16: Nirenberg and Khorana decipher the genetic code
5
plain
2025-04-03T11:18:42-04:00
“We found that poly-U stimulated the incorporation of the amino acid phenylalanine.”
Deciphering of the very first codon was achieved by Marshall Nirenberg (1927-2010). Nirenberg studied zoology at the University of Florida and obtained his Ph.D. from the University of Michigan in biochemistry in 1957. He spent the remainder of his career at the National Institutes of Health, first as a postdoctoral fellow and eventually as Head of Section and Laboratory Chief. He won the National Medal of Science in 1964, the National Medal of Honor in 1968, and in the same year the Nobel Prize, which he shared with Khorana (and Holley who we will come to in the next chapter).
Nirenberg reported his achievement at an International Congress of Biochemistry held in Moscow: “In August 1961, more than 5,000 scientists came to Moscow for five days of research talks at the International Congress of Biochemistry. A couple of days in, Matt Meselson, a friend of Crick’s, told him the news: The first word of the genetic code had been solved, by somebody else. In a small Friday afternoon talk at the Congress, in a mostly empty room, Marshall Nirenberg—an American biochemist and a complete unknown to Crick and Brenner—reported that he had fed a single repeated letter into a system for making proteins, and had produced a protein made of repeating units of just one of the amino acids. The first word of the code was solved. And it was clear that Nirenberg’s approach would soon solve the entire code.” [B. Goldstein 2015]. According to Meselson, who attended the Congress, “Not only did I meet him then—upon hearing his talk, the first one, in a small Classroom, I went up and hugged him.”
One more (possibly hallucinatory) story: The author of this eBook was in Moscow that summer as part of a trip around the world after graduating from high school. I think I met Nirenberg upon my arrival, who told me he was going to report something exciting! Of course, I was too young to appreciate what he was about to announce.
As Nirenberg recounts in the video, his breakthrough was the discovery that a synthetic RNA polymer of uridylic acid stimulated the incorporation of phenylalanine into protein using an extract of E. coli. Given that Crick, Barnett, and Watts-Tobin (Chapter 10) had inferred that the code must be based on units of three nucleotides, Nirenberg’s historic discovery meant that the codon for phenylalanine was a triplet of uridylic acid.
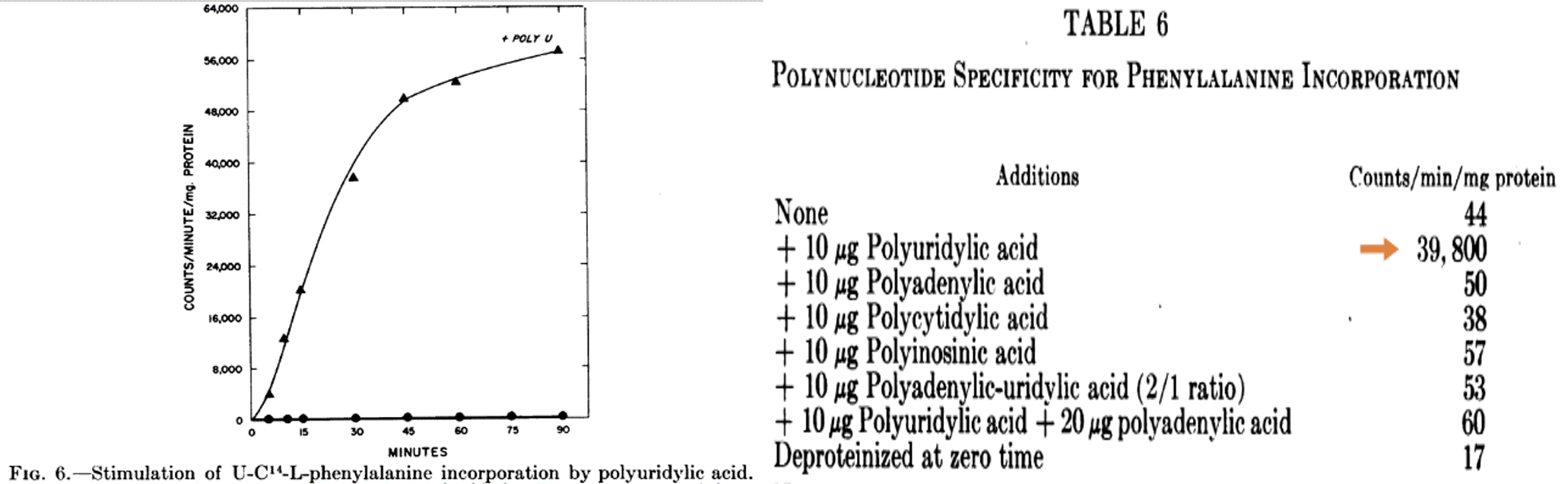
Nirenberg’s discovery with his postdoctoral fellow Matthaei was published in the same year as the Congress. Figure 6 from the publication showed that polyuridylic acid stimulated the incorporation of radioactive phenylalanine into protein by the extract. Table 6 showed that polyuridylic acid (red arrow added) but not other polynucleotides was responsible for the stimulation.
In a footnote to their publication, Nirenberg and Matthaei thank two prominent colleagues at the NIH, Leon Heppel and Maxine Singer “for samples of these polynucleotides.” Singer devoted a major portion of her laboratory’s effort to studying polynucleotide phosphorylase. Grunberg-Manago visited Singer at the NIH and they were friends. And Singer well appreciated the utility of Grunberg-Manago’s enzyme: “Polyribonucleotides of known composition…could easily be synthesized. For example, polycytidylic acid, a polymer of only cytidylic residues, was easily prepared.” It is therefore disappointing that Grunberg-Manago’s discovery with Ochoa of the enzyme that made it possible for Singer to produce these polynucleotides was not acknowledged (cited) by Nirenberg and Matthaei in their publication. Thus, as noted in the previous chapter, Grunberg-Manago’s impactful discovery of polynucleotide phosphorylase was not recognized by the Nobel Committee or by the pioneering scientists who exploited it to help crack the genetic code.
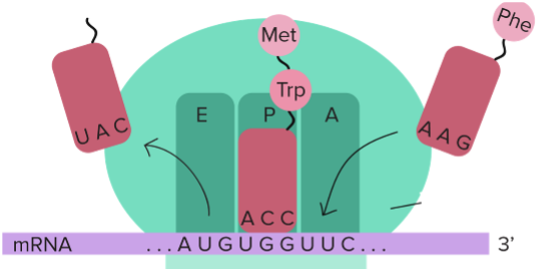
A further major advance in cracking the code was published three years later by Nirenberg and postdoctoral fellow Philip Leder. Nirenberg and Leder discovered that trinucleotides (but not dinucleotides) could be used to promote the binding of specific aminoacyl transfer RNAs to ribosomes. As depicted in the cartoon and as we come to in the next chapter, transfer RNAs (tRNAs or sRNAs as in the Table) are adaptors between amino acids and messenger RNA. Charged tRNAs enter the “A” site of the ribosome (phenylalanine-tRNA or Phe in the cartoon) where the anti-codon (AAG) of the charged tRNA pairs with the codon in the A site (UUC in the cartoon, which along with UUU is one of two synonymous codons for phenylalanine).
Nirenberg and Leder’s found that triplets could substitute for messenger RNA in promoting the binding of charged tRNAs to the ribosome. Thus, and as shown in the Table) the triplets mimicked individual codons. In this way, they showed that UUU promoted binding to ribosomes of phenylalanine-tRNA, AAA binding of lysine-tRNA, and CCC binding of proline-tRNA (highlighted with red arrows).
The next major advance in cracking the code was made by Har Gobind Khorana (1922-2011). Born in British India, Khorana attended Punjab University and then obtained his Ph.D. from the University of Liverpool in 1948. Next, and notably, Khorana did a postdoc in Cambridge from 1950-1952 with future Nobel Laureate Alexander Todd (Chapter 4) who had helped determine the structure of purines and pyrimidines. Khorana continued his studies on nucleic acids at the University of British Columbia (1952-1960). He then became a professor at the University of Wisconsin (1960-1970), where he did his breakthrough research, winning the Nobel Prize in 1968. Khorana moved to MIT in 1970 where he remained for the rest of his career.
Taking advantage of his training with Todd, Khorana chemically synthesized a variety of double-stranded deoxyribonuclotides of defined sequence. He then used these as templates for the synthesis of RNAs of extended length by DNA-dependent RNA polymerase. (Recall that Grunberg-Manago’s polynucleotide phosphorylase turned out to be an RNase, not a template-dependent RNA polymerase. DNA-dependent RNA polymerase was discovered in 1960 and was used by Khorana in generating synthetic RNAs.)
Khorana published prolifically. Here we focus on one of his seminal reports in which he generated an alternating copolymer of uridylic acid and cytodylic acid (poly-UC) using as a template for RNA polymerase a chemically-generated, double-stranded deoxy-TC:AG and using UTP and CTP as substrates. Using poly-UC as a template for protein synthesis, Khorana and co-workers discovered that it generated the alternating copolymer serine-leucine. Given that Nirenberg had previously assigned UCU as a serine codon, Khorana could now assign CUC as a leucine codon. Khorana’s results also provided further evidence that the code is triplet in that an alternating copolymer of U and C would only generate alternating UCU and CUC codons if the code were triplet.
Eventually, it became possible to assign an amino acid to 61 of the 64 possible triplets in the genetic code (Table). The remaining three, UAA, UAG, and UGA, do not specify amino acids. Rather, they serve as “stop” codons at the end of open-reading frames. Note as predicted by Crick et al. the code is degenerate with many amino acids being specified by two or more synonymous codons. Sometimes referred to as the “Rosetta Stone of Life”, the elucidation of the entire genetic code represents one of the major landmarks in the history of molecular biology.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}